AI per il Turismo
Giornata 1 — Fondamenti tecnici, strategia e prompting
2 marzo 2026
Obiettivi di apprendimento
Al termine della giornata sarai in grado di:
- Spiegare come funziona un LLM (tokenizzazione, transformer, generazione)
- Distinguere fine-tuning, RAG e prompting e scegliere l'approccio corretto
- Capire cosa sono gli agenti AI e i loro limiti attuali
- Scrivere prompt strutturati ed efficaci per casi d'uso turistici
- Identificare opportunità concrete nella tua attività
- Applicare le regole base di sicurezza e conformità GDPR
Contesto del corso
Chi sono
- PhD in Physics, AI Engineer
- Consulente e formatore AI
- Focus su applicazioni AI per PMI
Come lavoriamo oggi
- Teoria + esempi concreti
- Domande in qualsiasi momento
- Esercizi pratici nel pomeriggio
Programma della Giornata
| Orario | Parte | Sessione | Argomenti |
|---|---|---|---|
| 10:30 – 11:00 | Mattina | Introduzione del corso |
|
| 11:00 – 11:30 | Mattina | Prima parte |
|
| 11:30 – 11:45 | ☕ Break | ||
| 11:45 – 13:00 | Mattina | Seconda parte |
|
| 13:00 – 14:00 | 🍽 Pranzo libero | ||
| 14:00 – 14:55 | Pomeriggio | Prima parte |
|
| 14:55 – 15:05 | ☕ Break | ||
| 15:05 – 15:50 | Pomeriggio | Seconda parte |
|
| 15:50 – 16:00 | Chiusura | Chiusura |
|
Il filo conduttore della giornata
- Panoramica AI nel turismo
- Come funziona un LLM
- Context Window
- Fine-tuning
- RAG
- Agenti AI
- Tools & Functions
- Strumenti pratici
- Opportunità nel turismo
- Prompting efficace
- Sicurezza & GDPR
AI nel Turismo: Panoramica
Definizioni · Stato dell'arte · Falsi miti · Il cambio di paradigma
AI, ML, Deep Learning, AI Generativa

- AI — sistemi che eseguono compiti tipicamente umani
- ML — apprende da dati, senza regole scritte a mano
- Deep Learning — ML con reti neurali profonde
- AI Generativa — produce testo, immagini, audio, codice
AI nel turismo: dove siamo oggi
Hotel e OTA
- Revenue management predittivo
- Chatbot prenotazioni
- Risposta automatica recensioni
Destinazioni
- Itinerari personalizzati
- Analisi sentiment turisti
- Previsione flussi
Agenzie
- Ricerca e confronto automatico
- Proposte viaggio generate
- Supporto post-vendita
Adozione ancora disomogenea: le grandi OTA sono anni avanti rispetto alle PMI
Cosa l'AI non è
| Mito | Realtà |
|---|---|
| "L'AI è sempre accurata" | Produce errori convincenti (allucinazioni) |
| "Capisce tutto come un umano" | Predice il prossimo token, non ragiona |
| "È autonoma e imprevedibile" | Segue distribuzioni statistiche sui dati |
| "Sostituirà tutti" | Automatizza task ripetitivi, non ruoli interi |
| "È troppo complessa per le PMI" | API e no-code abbassano la barriera d'ingresso |
Il cambio di paradigma
AI di ricerca (pre-2020)
- Modelli specializzati per singolo task
- Richiedeva grandi dataset etichettati
- Accessibile solo a grandi aziende
- Output: classificazioni, previsioni numeriche
AI Generativa (oggi)
- Foundation models: un unico modello per centinaia di task
- Si istruisce via linguaggio naturale
- API accessibili a chiunque
- Output: testo, immagini, codice, audio
Challenge

Large Language Models
Come funzionano i modelli linguistici di grandi dimensioni
Cos'è un LLM
Un Large Language Model è una rete neurale addestrata a predire il prossimo token in una sequenza di testo.
- "Large" = miliardi di parametri (GPT-4: ~1.8T stimati)
- "Language" = opera su testo (e ora anche immagini, audio)
- "Model" = una funzione matematica appresa dai dati
Tokenizzazione: il testo diventa numeri
Prima di elaborare il testo, l'LLM lo converte in token (frammenti di parole).
- ~1 token ≈ 0.75 parole in inglese / ~0.6 parole in italiano
- Il costo API si misura in token (input + output)
- Parole rare o tecniche → più token → più costose
Strumento interattivo: platform.openai.com/tokenizer
L'architettura Transformer (semplificata)
Pre-training: imparare a predire
Cosa succede
- Input: trilioni di parole da internet, libri, codice
- Obiettivo: predire il token successivo
- Durata: settimane su migliaia di GPU
- Costo: decine–centinaia di milioni di $
Cosa apprende
- Grammatica e sintassi
- Fatti sul mondo
- Ragionamento logico di base
- Stili di scrittura diversi
Post-training: da predittore a assistente
- SFT — coppie (istruzione → risposta ideale) scritte da umani
- RLHF — valutatori umani confrontano risposte, il modello impara cosa preferiscono
- Risultato: il modello "conversa" invece di completare frasi
Parametri di generazione
| Parametro | Effetto | Esempio uso |
|---|---|---|
temperature |
0 = deterministico, 1 = creativo, >1 = caotico | 0.2 per FAQ, 0.9 per copywriting |
top_p |
Tronca al top P% di probabilità cumulativa | 0.9 default sicuro |
max_tokens |
Limite di token generati | 150 per tweet, 2000 per articolo |
stop |
Stringa che interrompe la generazione | "\n\n" per risposte brevi |
I principali modelli oggi
Closed vs open source models
Proprietari (third party APIs)
- Nessuna infrastruttura da gestire
- Aggiornamenti automatici
- Costo variabile per token
- Dati invitati al provider
- Esempio: OpenAI, Anthropic, Google
Open-source / open-weight
- Controllo totale dei dati
- Costo fisso (hardware)
- Richiede competenze tecniche
- Personalizzazione completa
- Esempio: LLaMA, Mistral, Phi
Consumer grade interfaces vs API
Consumer grade interfaces (ChatGPT, Claude.ai, Gemini)
- Uso manuale, sessione per sessione
- Nessuna integrazione con sistemi aziendali
- Adatte per sperimentazione e uso individuale
- Dati non usati per training (piano paid)
API (OpenAI API, Claude API, etc.)
- Integrabile in app, CRM, PMS, sito web
- Automatizzabile e scalabile
- Richiede sviluppo tecnico (o no-code)
- Fatturazione a consumo
Come scegliere il modello: criteri per PMI
- Qualità del task — modelli top solo se il task è critico (es. risposta a ospiti VIP)
- Costo per chiamata — verifica il pricing: input e output token hanno prezzi diversi
- Latenza — chatbot real-time richiede modelli veloci (es. GPT-5 mini, Claude Haiku)
- Lingua italiana — testa esplicitamente: non tutti i modelli performano uguale in italiano
- Conformità dati — verifica DPA, data residency (EU), termini di utilizzo
Challenge
Context Window
Memoria di lavoro del modello: limiti e implicazioni pratiche
Cos'è la context window
La context window è la quantità massima di testo che il modello può "vedere" in un singolo momento di elaborazione.
| Modello | Context window | ≈ Parole italiane |
|---|---|---|
| GPT-4o | 128.000 token | ~96.000 |
| Claude 3.5 Sonnet | 200.000 token | ~150.000 |
| Gemini 2 Pro | 2.000.000 token | ~1.500.000 |
| GPT-4o mini | 128.000 token | ~96.000 |
Cosa succede quando il contesto è pieno
- Il modello non può elaborare più testo: la chiamata API restituisce un errore
- Alcune implementazioni "tagliano" le parti più vecchie della conversazione
- Il modello "dimentica" le informazioni tagliate: nessuna memoria persistente nativa
- La qualità delle risposte degrada se il contesto è molto lungo (lost-in-the-middle)
Gestire il contesto in applicazioni reali
Strategie software
- Riassunto progressivo — riassumi la chat ogni N turni
- Finestra scorrevole — mantieni solo gli ultimi K scambi
- RAG — recupera solo i pezzi rilevanti (→ sezione 5)
- Estrazione entità — salva in DB i fatti importanti
Implicazioni di costo
- Token di input si pagano ad ogni chiamata
- Conversazione lunga = costo crescente
- Tenere il system prompt corto conta
- Modelli con caching (Claude) riducono i costi
Context window nel turismo
| Scenario | Token stimati | Strategia |
|---|---|---|
| Chatbot prenotazioni (chat breve) | 1.000–5.000 | Nessun problema, modello mini |
| Analisi di 50 recensioni | ~20.000 | Batch, un'analisi per volta |
| Q&A su catalogo completo (500 prodotti) | >100.000 | RAG obbligatorio |
| Risposta singola a cliente | 200–800 | API diretta, economico |
La tendenza: context window crescenti
- 2023: GPT-4 con 8k → 32k token
- 2024: Claude con 200k, Gemini con 1M token
- 2025: Gemini 2.0 con 2M token (~1.500 pagine)
- Direzione: context window "illimitata" a lungo termine
Challenge
Fine-tuning
Addestrare un modello sui propri dati
Il continuum dell'adattamento
Tipi di addestramento a confronto
| Fase | Dati | Chi lo fa | Costo |
|---|---|---|---|
| Pre-training | Trilioni di token da internet | Solo i lab (OpenAI, Anthropic…) | $10M–$100M+ |
| Supervised FT | Poche centinaia–migliaia di esempi | Aziende, sviluppatori | $100–$10.000 |
| RLHF / RLAIF | Preferenze umane o AI | Principalmente i lab | Elevato |
| Prompting | Esempi nel testo | Chiunque | Costo chiamata API |
Full fine-tuning vs LoRA
Full fine-tuning
- Aggiorna tutti i parametri del modello
- Massima capacità di adattamento
- Richiede GPU di alto livello
- Rischio di "dimenticare" conoscenza base (catastrophic forgetting)
LoRA / PEFT
- Aggiunge piccoli adattatori al modello base
- Addestra solo una frazione dei parametri (<1%)
- GPU consumer grade sufficienti
- Il modello base rimane intatto
- Tecnica dominante oggi per fine-tuning locale
Quando vale la pena il fine-tuning
- Il modello deve adottare uno stile di comunicazione molto specifico (tono brand, registro)
- Task ripetitivo con formato di output rigido (es. JSON strutturato, moduli specifici)
- Prompting lungo che si ripete ogni volta: il fine-tuning "incorpora" le istruzioni
- Hai centinaia di esempi di alta qualità già validati
Requisiti: dati, costi, infrastruttura
Dati
- Min. 50–100 esempi (qualità > quantità)
- Formato: JSONL con prompt/completion
- Devono essere puliti e rappresentativi
Costo (API)
- OpenAI FT: ~$8 / 1M token di training
- Training una tantum + inference continua
- Hosting del modello può avere costo fisso
Infrastruttura
- Via API: nessuna infrastruttura
- Self-hosted: GPU con 16–80 GB VRAM
- Cloud ML: Vertex AI, SageMaker, RunPod
Esempio: chatbot specializzato per un hotel
Senza fine-tuning
Prompt: "Sei l'assistente di Hotel Bellavista.
Rispondi in modo caldo e professionale.
Ecco le nostre politiche: [500 token]
Ecco i nostri servizi: [800 token]
Domanda cliente: check-out tardivo?"~1.400 token di contesto ad ogni chiamata
Con fine-tuning
Prompt: "Domanda cliente:
check-out tardivo?"Tono, politiche e stile già incorporati nel modello
~30 token di contesto ad ogni chiamata
Fine-tuning vs prompting: la scelta
| Criterio | Usa prompting | Considera fine-tuning |
|---|---|---|
| Tempo disponibile | Disponibile subito | Settimane per dati + training |
| Volume di richieste | Basso / medio | Molto alto (costo contesto) |
| Stile output | Generico o semi-specifico | Molto rigido o branded |
| Dati disponibili | Pochi o nessuno | Decine-centinaia di esempi |
| Competenze tecniche | Nessuna | Sviluppatore o ML engineer |
Challenge
RAG — Retrieval Augmented Generation
Collegare un LLM ai tuoi dati senza addestrarlo
Il problema: l'LLM non conosce i tuoi dati
Cosa l'LLM non sa
- Il tuo listino prezzi aggiornato
- Le politiche specifiche del tuo hotel
- Le disponibilità in tempo reale
- I documenti interni aziendali
- Le notizie degli ultimi mesi
Le (cattive) alternative
- Mettere tutto nel prompt → contesto esplode, costi alti
- Fine-tuning → non impara fatti aggiornabili, solo stile
- Ignorare il problema → il modello allucinano
Architettura RAG - Concetto di base

Architettura RAG - Diagramma di un'applicazione
Embedding: testo come coordinate
Un modello di embedding converte testo in un vettore di numeri che rappresenta il suo significato.
- Testi con significato simile → vettori vicini nello spazio
- La similarità coseno misura quanto due testi sono semanticamente correlati
- Modelli di embedding: OpenAI text-embedding-3, Cohere, sentence-transformers
Embedding: lo spazio vettoriale

Embedding: vettori di parole

Vector database: cos'è e come funziona
Database tradizionale
Cerca parole esatte
SELECT * FROM faq
WHERE testo LIKE '%check-out%'Non trova "orario di partenza"
Vector database
Cerca per significato semantico
query = embed("a che ora devo lasciare la stanza?")
results = db.search(query, top_k=3)Trova check-out, partenza, late check-out…
Soluzioni comuni per database vettoriali: Pinecone, Weaviate, Chroma, pgvector (PostgreSQL), Qdrant
Pipeline RAG: passo per passo
- Caricamento documenti — PDF, Word, database, sito web
- Chunking — dividi in pezzi di 200–500 token con overlap
- Embedding — converti ogni chunk in vettore
- Indicizzazione — salva i vettori nel vector DB
- — runtime —
- Embedding domanda — converti la domanda utente in vettore
- Ricerca — trova i top-3/5 chunk più simili
- Augmentation — inserisci i chunk nel prompt
- Generation — l'LLM risponde basandosi sui chunk
RAG nel turismo: esempi pratici
FAQ dinamiche hotel
- Manuale operativo → chunked
- Chatbot risponde su politiche, orari, servizi
- Aggiornamento: caricare nuovo PDF
Catalogo tour
- 500 schede tour → indicizzate
- "Tour adatto a bambini con snorkeling" → top-3 tour
- Risposta con dettagli precisi
Prezzi e disponibilità
- Aggiornamento notturno dal PMS
- Chatbot risponde con dati freschi
- Nessun rischio di informazioni obsolete
RAG vs fine-tuning: tabella comparativa
| Aspetto | RAG | Fine-tuning |
|---|---|---|
| Aggiornamento dati | Facile (ricarica documenti) | Costoso (riaddestrare) |
| Trasparenza | Alta (si vede la fonte) | Bassa (dati incorporati) |
| Allucinazioni su fatti | Ridotte (chunk come ancoraggio) | Presenti |
| Stile di output | Non cambia il comportamento del modello | Modifica stile e comportamento |
| Setup tecnico | Medio (vector DB, pipeline) | Medio-alto (dataset, GPU) |
Limiti del RAG
- Qualità del chunking — chunk mal tagliati = contesto frammentato = risposta sbagliata
- Domande multi-hop — "confronta il prezzo del tour X con il tour Y" richiede più recuperi
- Dati non testuali — tabelle complesse, immagini, PDF con layout complesso sono difficili
- Latenza aggiuntiva — la ricerca vettoriale aggiunge 50–300ms per query
- Hallucination non eliminata — il modello può ancora ignorare il contesto fornito
Challenge
Agenti AI
Sistemi autonomi che pianificano e agiscono nel mondo reale
La differenza: LLM, Assistente, Agente
- Predice il prossimo token
- Nessuna memoria
- Nessun tool
- Risponde in linguaggio naturale
- Mantiene il contesto
- Segue istruzioni di sistema
- Pianifica task complessi
- Usa strumenti ed esegue azioni
- Osserva risultati e itera
Il ciclo ReAct: Reason → Act → Observe
Pianificazione e memoria negli agenti
Tipi di memoria
- In-context — tutto nella conversazione corrente
- Esterna — database, file, vettori persistenti
- Procedurale — istruzioni nel system prompt
- Episodica — log di sessioni precedenti
Tipi di pianificazione
- Chain-of-thought — passo dopo passo nel testo
- Tree-of-thought — esplora più percorsi
- Plan-and-execute — piano completo poi esecuzione
- ReAct — interleave ragionamento e azioni
Multi-agent systems
Concetti chiave
- Specializzazione — ogni agente ha un dominio preciso e tool dedicati
- Orchestrazione — l'orchestratore assegna task, raccoglie risultati e risolve conflitti
- Parallelismo — più agenti lavorano in simultanea, riducendo la latenza
- Composabilità — i sotto-agenti sono riutilizzabili in altri workflow
Framework
- LangGraph — grafi di agenti con stato esplicito
- CrewAI — agenti con ruoli e obiettivi in linguaggio naturale
- AutoGen — conversazioni multi-agente (Microsoft)
- Claude MCP — protocollo standard per tool e agenti
Agenti AI nel turismo
🏨 Prenotazione automatica
Riceve richiesta, verifica disponibilità PMS, applica politiche tariffarie, genera conferma e invia email al cliente
💰 Ottimizzazione revenue
Analizza storico, eventi locali e competitor → propone automaticamente il piano tariffario settimanale al revenue manager
🔍 Monitoraggio competitor
Scansiona OTA ogni ora, confronta tariffe con le proprie, notifica il team se il gap supera una soglia definita
⭐ Gestione recensioni
Monitora TripAdvisor, Google, Booking in tempo reale, bozza risposte personalizzate e le invia dopo approvazione umana
🗺️ Assistente viaggiatore
Pianifica itinerari su misura, prenota ristoranti e attività, risponde a domande pre e post soggiorno in linguaggio naturale
📊 Report operativi
Aggrega dati da PMS, CRM e canali OTA ogni mattina → genera report KPI con anomalie evidenziate e pronto per il briefing
Rischi e limitazioni degli agenti
- Errori a cascata — un errore in un passo si amplifica nei passi successivi
- Loop infiniti — l'agente non termina se non trova la condizione di stop
- Prompt injection — dati esterni manipolati per dirottare l'agente
- Costi non prevedibili — ogni iterazione consuma token: task complessi costano molto
- Azioni irreversibili — inviare email, modificare database, spendere soldi
Quando gli agenti sono affidabili oggi?
| Scenario | Affidabilità | Note |
|---|---|---|
| Task semplici con strumenti chiari | Alta | 1-3 passi, tool ben definiti |
| Ricerca e sintesi di informazioni | Alta | Nessuna azione irreversibile |
| Workflow multi-step (5-10 passi) | Media | Richiede supervisione |
| Task aperti, goal ambiguo | Bassa | Non raccomandato in produzione |
| Azioni finanziarie autonome | Non consigliato | Supervisione umana sempre |
Challenge
Tools e Function Calling
Come un LLM esegue azioni nel mondo reale
Dall'LLM al mondo reale
Un LLM da solo produce solo testo. Per fare qualcosa, ha bisogno di strumenti (tools).
Function calling: definire strumenti per l'LLM
Ogni strumento viene definito con uno schema che il modello usa per generare chiamate corrette.
{
"name": "verifica_disponibilita",
"description": "Controlla disponibilità camere nel PMS",
"parameters": {
"tipo_camera": {
"type": "string",
"enum": ["standard", "deluxe", "suite"],
"description": "Tipo di camera richiesta"
},
"data_arrivo": {
"type": "string",
"format": "date",
"description": "Data arrivo (YYYY-MM-DD)"
},
"notti": {
"type": "integer",
"description": "Numero di notti"
}
},
"required": ["tipo_camera", "data_arrivo", "notti"]
}Esempi di tool nel turismo
| Tool | Azione | Sistema integrato |
|---|---|---|
verifica_disponibilita |
Controlla camere libere | PMS (Opera, Mews, Cloudbeds) |
crea_prenotazione |
Prenota e conferma | PMS + Channel Manager |
cerca_meteo |
Previsioni per destinazione | API meteo |
invia_notifica |
Email/SMS al cliente | CRM, Mailchimp, Twilio |
aggiorna_tariffa |
Modifica prezzi | Revenue management system |
Architettura multi-agente
MCP: Model Context Protocol
MCP è uno standard aperto (Anthropic, 2024) per collegare LLM a strumenti e fonti di dati in modo interoperabile.
Prima di MCP
- Ogni integratore costruisce il proprio formato
- Tool non riutilizzabili tra modelli diversi
- Manutenzione moltiplicata
Con MCP
- Server MCP standard per ogni sistema
- Funziona con Claude, GPT-4, Gemini…
- Ecosistema di server già pronti (Google Drive, GitHub, database…)
Function calling classico: overhead di contesto
- Ogni risultato intermedio entra nel contesto: il modello deve elaborare ogni risposta prima di procedere
- Con N fonti: 2N + 1 round-trip, occupazione di contesto O(N)
- Contesto saturo → degradazione delle performance (lost-in-the-middle); latenza e costo crescono linearmente
Programmatic Tool Calling
Function calling classico
Programmatic Tool Calling
# Il modello genera questo codice:
results = web_search("AI news")
content_list = []
for r in results:
content = web_fetch(r.url)
content_list.append(content)
write_blog(content_list)1 round-trip · solo l'output finale rientra nel contesto LLM
Code Execution: abilitazione e impatto
Come abilitarlo (Anthropic API)
tools = [
# 1. Aggiungere l'execution environment
{"type": "code_execution_20250522",
"name": "code_execution"},
# 2. Segnare i tool richiamabili da codice
{
"name": "query_database",
"description": "...",
"input_schema": {...},
"allowed": ["code_execution"]
}
]Il tool code_execution fornisce la sandbox; allowed espone la funzione come callable nell'ambiente.
Capacità sbloccate
- Batch processing — cicli
forsu N elementi, eseguiti in parallelo - Conditional tool selection —
if/elsesul risultato di un tool per decidere il tool successivo - Data filtering locale — trasformazione e aggregazione dei risultati prima di inserirli nel contesto
- Riduzione round-trip — da 2N+1 chiamate a 1 (richiesta) + 1 (risposta finale)
Benchmark Anthropic: contesto a parità di task circa 4× inferiore rispetto al function calling classico.
Ottimizzazioni avanzate per agenti ad alta efficienza
Dynamic Web Filtering
- Il sistema filtra automaticamente il contenuto delle pagine web recuperate durante il web search
- Solo le sezioni semanticamente rilevanti alla query entrano nel contesto
- Riduzione token di input: 24 % in media (range 33–62 % a seconda del contenuto)
- Attivazione: aggiungere il tool
web_search— il filtering è applicato automaticamente
Tool Search
- Con molti server MCP, caricare tutte le definizioni in contesto è proibitivo
- Un tool speciale
search_toolcerca le definizioni rilevanti su richiesta, via regex o query BM25 - Risparmio: ~95 % del contesto occupato da definizioni di tool
- Deferred loading: la definizione viene caricata solo al momento dell'uso e rimossa dopo, liberando spazio
Tool Use Examples
- Aggiungere esempi di input nella definizione del tool (approccio few-shot a livello di schema)
- Cinque esempi sono sufficienti nella maggior parte dei casi
- Accuratezza nella chiamata corretta del tool: 70 % → 90 %
- Particolarmente utile per tool con molti parametri o input strutturati complessi
Challenge
Pranzo
Si riprende nel pomeriggio
Strumenti AI: guida pratica
ChatGPT, Claude, Copilot e Gemini — accesso, costi e prime attività concrete
Il panorama degli strumenti grade
| Strumento | Azienda | Punto di forza | Gratis? |
|---|---|---|---|
| ChatGPT | OpenAI | Uso generale, il più noto; immagini (DALL-E 3) | Sì (limitato) |
| Claude.ai | Anthropic | Scrittura lunga, analisi documenti PDF | Sì (limitato) |
| Microsoft Copilot | Microsoft | Integrato in Outlook, Teams, Excel, Word | Sì (web) |
| Google Gemini | Integrato in Gmail, Docs, Drive, Sheets | Sì (base) |
ChatGPT — chatgpt.com
Per il turismo
- Rispondere a recensioni positive e negative
- Scrivere post social (Instagram, Facebook)
- Creare itinerari personalizzati su richiesta
- Tradurre comunicazioni in più lingue
- Generare descrizioni di camere e pacchetti
Piani
- Free — GPT-5.2 limitato
- Plus — $20/mese · GPT-5.2 illimitato, file, immagini
Vai su chatgpt.com → incolla una recensione negativa recente → scrivi:
"Rispondi in tono professionale e comprensivo, max 100 parole, in italiano."
Claude.ai — claude.ai
Per il turismo
- Analizzare documenti lunghi (contratti, policy, PDF)
- Rispondere a domande sul contenuto di un documento
- Scrivere testi articolati nel tono del brand
- Riepilogare feedback e identificare pattern
- Ragionare su scenari complessi (scelte tariffarie, offerte)
Piani
- Free — Claude Sonnet, Haiku (uso giornaliero limitato)
- Pro — $18/mese · Claude Opus, uso esteso, file, Progetti
Vai su claude.ai → carica il PDF della tua policy di cancellazione → scrivi:
"Se un ospite cancella 8 giorni prima, ha diritto a rimborso? Rispondi in modo chiaro e sintetico."
La funzione Progetti (piano Pro) salva contesto fisso — policy, tono, istruzioni — senza doverlo riscrivere ad ogni conversazione.
Microsoft Copilot — copilot.microsoft.com
Per il turismo
- Outlook — bozza email di benvenuto, pre-arrivo, follow-up
- Teams — riassunto riunione con action items
- Excel — analisi dati prenotazioni, grafici occupazione
- Word — contratti tipo, offerte commerciali
- Web (gratuito) — ricerca con fonti, risposta in tempo reale
Piani
- Free — copilot.microsoft.com (GPT-5.1 + web search)
- M365 Copilot — $30/utente/mese · integrato nelle app Office
Vai su copilot.microsoft.com → scrivi:
"Scrivi un'email di benvenuto per un ospite che arriva domani al mio boutique hotel a Firenze. Tono caldo, max 80 parole."
Se usi già Microsoft 365, verifica con il tuo fornitore IT se il piano M365 Copilot è già attivabile sul tuo tenant.
Google Gemini — gemini.google.com
Per il turismo
- Gmail — bozza risposte a richieste di prenotazione
- Google Docs — generazione offerte, guide locali, comunicati
- Google Sheets — analisi dati con linguaggio naturale
- Ricerca web in tempo reale (prezzi competitor, eventi locali)
- Analisi immagini — foto struttura, menu, allestimenti
Piani
- Free — Gemini 2.5 Flash su gemini.google.com
- Google One AI Premium — €21.99/mese · Gemini 3.1 Pro + Workspace
Vai su gemini.google.com → incolla 5–10 recensioni recenti → scrivi:
"Analizza queste recensioni: elenca i 3 punti di forza e le 2 aree di miglioramento più citati."
Chi usa già Google Workspace ottiene il valore maggiore dal piano a pagamento, grazie alle integrazioni native con Gmail e Drive.
Quale strumento scegliere
| Se… | Usa | Piano |
|---|---|---|
| Usi già Microsoft 365 (Outlook, Teams, Excel) | Microsoft Copilot M365 | $30/utente/mese |
| Usi già Google Workspace (Gmail, Drive) | Google Gemini | €21.99/mese |
| Vuoi analizzare documenti e scrivere testi articolati | Claude.ai | Free per iniziare, Pro ($18/mese) per uso quotidiano |
| Vuoi l'opzione più versatile, con generazione immagini | ChatGPT | Free per iniziare, Plus ($20/mese) per uso quotidiano |
Challenge
Identificare Opportunità
Dove l'AI crea valore nella tua attività turistica
Framework: mappare i processi ripetitivi
Il punto di partenza per identificare opportunità AI è una mappa dei processi aziendali ripetitivi.
Segnali che un task è adatto all'AI
- Si ripete più di 10 volte al giorno
- Richiede elaborazione testo / linguaggio
- Ha un output definibile e verificabile
- Un nuovo collaboratore lo imparerebbe in < 1 ora
- Non richiede empatia profonda o relazione
Segnali che un task NON è adatto
- Ogni caso è unico e complesso
- Richiede giudizio etico o legale
- Relazione umana è il valore centrale
- Errori hanno conseguenze gravi
- Dati strutturati puri (usa DB classico)
Matrice impatto / sforzo per l'AI
- Quick wins: risposta a recensioni, generazione post social, FAQ chatbot, traduzione email ospiti
- Strategici: revenue management AI, prenotazioni automatizzate, RAG su catalogo, agente multicanale
Adatti vs non adatti all'AI generativa
| Adatti | Non adatti (o non ancora) |
|---|---|
| Rispondere a email tipo con personalizzazione | Gestione conflitti complessi con ospiti |
| Generare descrizioni di camere / pacchetti | Decisioni legali (rimborsi, danni) |
| Riepilogare feedback e recensioni | Supervisione operativa fisica |
| Proporre itinerari personalizzati | Relazioni con clienti VIP ad alto valore |
| Tradurre comunicazioni multilingua | Valutazioni HR su performance collaboratori |
Casi d'uso per settore
Hotel / B&B
- Chatbot prenotazioni e FAQ
- Check-in/out automatizzato via chat
- Risposta automatica a recensioni
- Upsell personalizzato pre-arrivo
- Sommario feedback mensile
Ristoranti
- Generazione descrizioni menu
- Risposta a prenotazioni e richieste dietetiche
- Post social automatizzati
- Analisi recensioni TripAdvisor
Agenzie viaggi / DMC
- Proposte itinerari personalizzati
- Ricerca e confronto fornitori
- Email follow-up automatiche
- Elaborazione briefing clienti
Esercizio: identifica 3 processi nella tua attività
- Pensa ai task che svolgi (o fa il tuo team) ripetutamente ogni settimana
- Per ognuno, valuta: Alta/Media/Bassa frequenza × Alto/Medio/Basso impatto se automatizzato
- Posizionalo sulla matrice impatto/sforzo
| Task | Frequenza | Impatto | Sforzo stimato |
|---|---|---|---|
| 1. | |||
| 2. | |||
| 3. |
Challenge
Prompting Efficace
Comunicare con i modelli AI in modo preciso e sistematico
Anatomia di un prompt: 5 componenti
Zero-shot, few-shot, chain-of-thought
Zero-shot
Nessun esempio, solo istruzione
"Classifica questa recensione come positiva o negativa: 'La colazione era fredda'"
Veloce, economico, sufficiente per task semplici
Few-shot
2-5 esempi prima del task
"Positiva: 'Vista mozzafiato' Negativa: 'Stanza piccola' Classifica: 'Colazione fredda'"
Migliora precisione e formato output
Chain-of-thought
Chiedi ragionamento esplicito
"Ragiona passo per passo: 1) Identifica il problema 2) Valuta il tono 3) Dai la classificazione"
Task complessi, ragionamento, calcoli
Prompt templating: strutture riutilizzabili
Un template è un prompt con variabili da riempire a runtime.
Sei il responsabile delle relazioni con gli ospiti di {{nome_struttura}}.
Hai ricevuto questa recensione su {{piattaforma}}:
---
{{testo_recensione}}
---
Scrivi una risposta professionale che:
- Ringrazi l'ospite per il feedback
- Risponda specificamente al punto principale
- {{istruzione_specifica}}
- Rimanga sotto {{max_parole}} paroleEsempio pratico: post social
Prompt
"Sei il social media manager di Agriturismo Le Colline. Scrivi 3 varianti di post Instagram per promuovere il weekend di degustazione vini del 15 marzo. Formato: - Emoji all'inizio - Max 150 caratteri - 3-5 hashtag rilevanti - Tono caldo e autentico"
Output atteso
🍷 Sabato 15 marzo vi aspettiamo tra i nostri vigneti per una degustazione indimenticabile. #agriturismo #vino #toscana 🌿 Weekend di gusto e natura: degustazione con vista sulle colline. Posti limitati! #wine #tuscany #weekend ✨ Ogni sorso racconta la nostra terra. Vi aspettiamo il 15 marzo. #degustazione #vino #italianwine
Esempio pratico: risposta a recensioni
Recensione (negativa)
Prompt
"Rispondi a questa recensione negativa. Tono: professionale e comprensivo. Riconosci i problemi specifici. Offri un contatto diretto. Max 100 parole. Non essere difensivo."
Output
Esempio pratico: itinerari personalizzati
Sei un esperto di turismo in Sicilia orientale.
Crea un itinerario di 5 giorni per:
- Coppia, 35-40 anni
- Interessi: storia greco-romana, cucina locale, passeggiate moderate
- Budget: medio-alto
- Periodo: aprile
- Base: Siracusa
- Senza guida: autonomi in auto
Per ogni giorno indica:
- Mattina / pomeriggio / sera
- Tempo di guida stimato
- 1 ristorante consigliato con specialità tipica
- 1 nota pratica (prenotazione consigliata, orari, ecc.)Esempi pratici: FAQ e descrizioni
FAQ automatizzate
"Dai questa policy di cancellazione: [testo policy] Rispondi a questa domanda di un ospite: 'Se cancello 10 giorni prima ricevo il rimborso completo?' Sii preciso, breve, in tono amichevole."
Descrizione pacchetto
"Scrivi una descrizione commerciale per questo pacchetto: - 3 notti suite vista mare - Colazione inclusa - Accesso SPA illimitato - Cena romantica (1 sera) - Prezzo: €480 a notte Target: coppie, occasioni speciali. Max 80 parole. Tono evocativo."
Errori comuni nel prompting
| Errore | Effetto | Soluzione |
|---|---|---|
| Prompt troppo vago | Output generico, inutilizzabile | Specifica formato, lunghezza, tono |
| Nessun contesto aziendale | Risposta generica, non branded | Aggiungi nome, settore, valori |
| Dire cosa NON fare solo | Il modello non sa cosa fare | Di' COSA vuoi, non solo cosa evitare |
| Task multipli in un prompt | Risultato mediocre su tutto | Un prompt = un task |
| Nessuna struttura output | Formato imprevedibile | Specifica: "rispondi in lista", "usa JSON" |
Debugging sistematico del prompt
Prompt per analisi recensioni
Analizza le seguenti recensioni di un hotel e produce un report strutturato.
Recensioni:
---
{{lista_recensioni}}
---
Per ogni recensione, identifica:
1. Sentiment complessivo: Positivo / Neutro / Negativo
2. Temi principali menzionati (max 3 per recensione)
3. Punteggio implicito 1-5
Poi produci:
- Top 3 punti di forza ricorrenti
- Top 3 aree di miglioramento
- 1 azione concreta raccomandata
Formato output: JSON strutturatoPrompt Engineering vs. Context Engineering
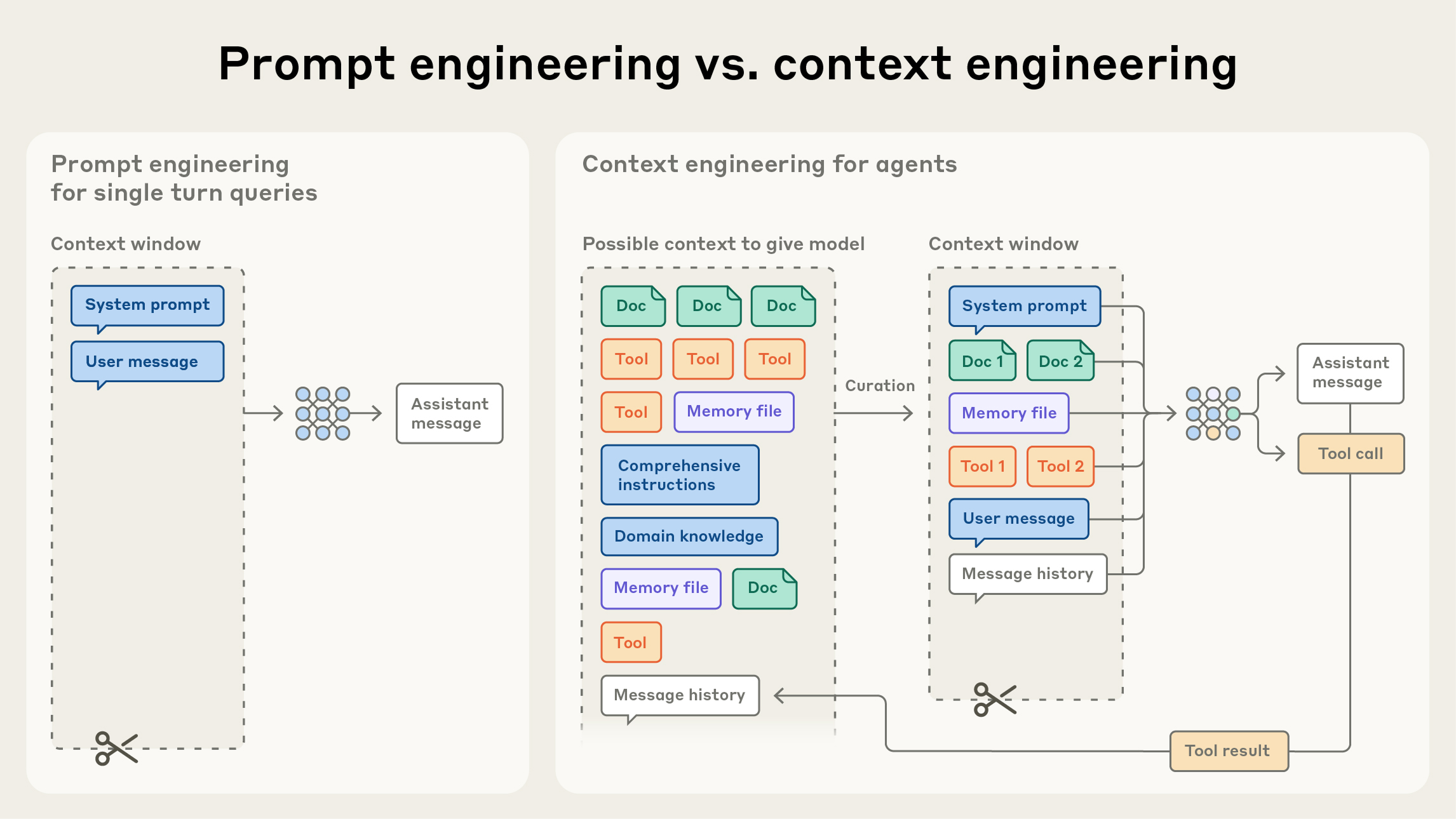
Prompt Engineering
Ottimizzazione del testo del singolo prompt: ruolo, istruzione, formato, vincoli, esempi few-shot.
Context Engineering
Progettazione dell'intero contesto passato al modello:
- Strumenti — quali tool sono disponibili e con quali definizioni
- Documenti recuperati — chunk RAG, risultati web, file di progetto
- Storia della conversazione — quali turni mantenere o compattare
- Output strutturati — risultati di tool call precedenti nel contesto
Challenge
Sicurezza e Privacy
GDPR, rischi pratici e uso responsabile dell'AI
GDPR e AI: obblighi e responsabilità
Principi GDPR rilevanti
- Minimizzazione dei dati — usa solo i dati necessari
- Limitazione della finalità — non riutilizzare dati per altri scopi
- Responsabilità — sei il titolare del trattamento
- Privacy by design — progetta con la privacy in mente
Cosa cambia con l'AI
- I dati inviati all'API possono essere usati per il training (controlla i termini)
- Decisioni automatizzate richiedono trasparenza (Art. 22)
- Profilazione ospiti → base giuridica necessaria
- Data breach include anche leak tramite prompt
Rischi specifici: cosa può andare storto
| Rischio | Descrizione | Impatto |
|---|---|---|
| Prompt injection | Un input malevolo altera il comportamento del modello | Dati esposti, azioni non autorizzate |
| Data leakage | Il modello "ricorda" dati sensibili inseriti nel contesto | Esposizione dati clienti/aziendali |
| Model inversion | Attacchi che estraggono dati dai parametri del modello | Rilevante solo per fine-tuning su dati sensibili |
| Allucinazioni nei dati fattuali | Il modello inventa prezzi, policy, informazioni legali | Danni reputazionali, contestazioni |
Regole pratiche: cosa non inserire mai in un prompt
- Dati personali identificativi (nome + email + telefono insieme)
- Numero carta di credito, dati bancari, documenti d'identità
- Credenziali di accesso (password, API key, token)
- Dati sanitari o preferenze sensibili degli ospiti
- Segreti industriali o contratti riservati
Per batch processing di dati clienti: usa sempre pseudonimizzazione e conserva la mappatura in locale.
Servizi AI con garanzie enterprise
Opzioni enterprise
- OpenAI Enterprise / API — dati non usati per training, SOC 2
- Azure OpenAI — data residency EU, isolamento tenant, DPA Microsoft
- Anthropic Claude API — dati non per training, privacy policy solida
- Google Vertex AI — data residency, GDPR compliance
Cosa verificare
- I dati vengono usati per training? (no per piani a pagamento)
- Dove sono processati i dati? (data residency)
- C'è un DPA (Data Processing Agreement) disponibile?
- Certificazioni: SOC 2, ISO 27001, GDPR?
Checklist: uso sicuro dell'AI in una PMI del turismo
- Ho firmato un DPA con il provider AI
- Shadow AI: i collaboratori non inseriscono dati personali clienti nei prompt
- Uso piani a pagamento (no training sui dati)
- Ho aggiornato il registro dei trattamenti
- Informativa privacy aggiornata (menzione tool AI)
- Output dell'AI verificati da umano prima di inviare
- Nessuna API key nel codice del sito / app
- Accesso agli strumenti AI limitato agli utenti necessari
- Auditing: Log delle operazioni AI critiche conservati
- Piano di risposta a data breach aggiornato
Challenge
Chiusura Giornata 1
Riepilogo · Risorse · Prossimi passi
Riepilogo — Fondamenti tecnici
Concetti chiave
- LLM = predizione statistica su scala enorme
- Token = unità base di costo e contesto
- Context window = memoria di lavoro del modello
- Fine-tuning = stile e formato, non nuovi fatti
- RAG = i tuoi dati + LLM senza addestrare
- Agenti = LLM + strumenti + autonomia limitata
- Function calling = interfaccia tra LLM e sistemi reali
Riepilogo — Strategia e prompting
Identificare opportunità
- Processi ripetitivi con output definibile
- Matrice impatto/sforzo
- Quick wins prima
Prompting efficace
- 5 componenti: Ruolo, Contesto, Compito, Formato, Vincoli
- Template riutilizzabili
- Itera un elemento alla volta
Sicurezza
- No dati sensibili nei prompt
- DPA con il provider
- Verifica umana degli output critici
Risorse per approfondire
Letture
- The Alignment Problem — Brian Christian
- Co-Intelligence — Ethan Mollick
- Anthropic Research Blog
- OpenAI Research
- Claude API Docs — guide tecniche e concetti approfonditi
Corsi online
- deeplearning.ai — corsi pratici, gratuiti
- fast.ai — ML applicato
- Prompt Engineering Guide
Strumenti da esplorare
- Claude.ai — interfaccia Anthropic
- ChatGPT — interfaccia OpenAI
- Perplexity — ricerca con AI
- Make / n8n — automazioni no-code con AI
- Dify / Flowise — RAG e chatbot no-code
Community
- r/LocalLLaMA (Reddit)
- Hugging Face community
Domande?
Grazie per la giornata.
Appuntamento al Giorno 2.
Glossario
Abbreviazioni e termini usati durante la giornata
Abbreviazioni e termini chiave
Turismo & Business
| OTA | Online Travel Agency — piattaforme di prenotazione online (Booking.com, Expedia, Airbnb) |
| PMS | Property Management System — gestionale hotel per prenotazioni, camere e fatturazione |
| CRM | Customer Relationship Management — sistema per gestire dati e relazioni con i clienti |
| KPI | Key Performance Indicator — indicatore chiave di performance aziendale |
| FAQ | Frequently Asked Questions — domande frequenti con risposte precompilate |
| DMC | Destination Management Company — operatore locale che organizza servizi turistici in loco |
| B2B / B2C | Business-to-Business / Business-to-Consumer — tipo di relazione commerciale |
AI & Tecnologia
| LLM | Large Language Model — modello AI addestrato su grandi quantità di testo |
| ML | Machine Learning — disciplina dell'AI che apprende da dati senza regole esplicite |
| RAG | Retrieval Augmented Generation — tecnica che collega un LLM a documenti esterni |
| API | Application Programming Interface — interfaccia per la comunicazione tra sistemi software |
| MCP | Model Context Protocol — standard Anthropic per collegare agenti AI a strumenti esterni |
| GPU | Graphics Processing Unit — processore specializzato usato per addestrare modelli AI |
| GDPR | General Data Protection Regulation — regolamento UE sulla protezione dei dati personali |
| DPA | Data Processing Agreement — accordo contrattuale sul trattamento dei dati con fornitori terzi |
| SOC 2 | Service Organization Control 2 — certificazione di sicurezza per fornitori cloud |