AI in Tourism
Day 1 — Technical Foundations, Strategy and Prompting
March 2, 2026
Learning Objectives
By the end of the day you will be able to:
- Explain how an LLM works (tokenisation, transformer, generation)
- Distinguish fine-tuning, RAG and prompting and choose the right approach
- Understand what AI agents are and their current limitations
- Write structured and effective prompts for tourism use cases
- Identify concrete opportunities in your business
- Apply the basic rules of security and GDPR compliance
Course Context
About me
- PhD in Physics, AI Engineer
- AI Consultant and Trainer
- Focus on AI applications for SMEs
How we work today
- Theory + concrete examples
- Questions at any time
- Practical exercises in the afternoon
Day Schedule
| Time | Part | Session | Topics |
|---|---|---|---|
| 10:30 – 11:00 | Morning | Course Introduction |
|
| 11:00 – 11:30 | Morning | First Part |
|
| 11:30 – 11:45 | ☕ Break | ||
| 11:45 – 13:00 | Morning | Second Part |
|
| 13:00 – 14:00 | 🍽 Lunch Break | ||
| 14:00 – 14:55 | Afternoon | First Part |
|
| 14:55 – 15:05 | ☕ Break | ||
| 15:05 – 15:50 | Afternoon | Second Part |
|
| 15:50 – 16:00 | Closing | Wrap-up |
|
The Day's Thread
- AI Overview in Tourism
- How an LLM works
- Context Window
- Fine-tuning
- RAG
- AI Agents
- Tools & Functions
- Practical Tools
- Opportunities in Tourism
- Effective Prompting
- Security & GDPR
AI in Tourism: Overview
Definitions · State of the Art · Common Myths · The Paradigm Shift
AI, ML, Deep Learning, Generative AI

- AI — systems that perform tasks typically done by humans
- ML — learns from data, without hand-written rules
- Deep Learning — ML with deep neural networks
- Generative AI — produces text, images, audio, code
AI in Tourism: where we stand today
Hotels & OTAs
- Predictive revenue management
- Booking chatbots
- Automated review responses
Destinations
- Personalised itineraries
- Tourist sentiment analysis
- Flow forecasting
Travel Agencies
- Automated search and comparison
- Generated travel proposals
- After-sales support
Adoption is still uneven: large OTAs are years ahead of SMEs
What AI is not
| Myth | Reality |
|---|---|
| "AI is always accurate" | It produces convincing errors (hallucinations) |
| "It understands everything like a human" | It predicts the next token — it doesn't reason |
| "It is autonomous and unpredictable" | It follows statistical distributions over data |
| "It will replace everyone" | It automates repetitive tasks, not entire roles |
| "It is too complex for SMEs" | APIs and no-code tools lower the barrier to entry |
The Paradigm Shift
Research AI (pre-2020)
- Specialised models for a single task
- Required large labelled datasets
- Accessible only to large companies
- Output: classifications, numerical predictions
Generative AI (today)
- Foundation models: one model for hundreds of tasks
- Instructed via natural language
- APIs accessible to anyone
- Output: text, images, code, audio
Challenge

Large Language Models
How large language models work
What is an LLM
A Large Language Model is a neural network trained to predict the next token in a sequence of text.
- "Large" = billions of parameters (GPT-4: ~1.8T estimated)
- "Language" = operates on text (and now also images, audio)
- "Model" = a mathematical function learned from data
Tokenisation: text becomes numbers
Before processing text, the LLM converts it into tokens (word fragments).
- ~1 token ≈ 0.75 words in English / ~0.6 words in Italian
- API cost is measured in tokens (input + output)
- Rare or technical words → more tokens → more expensive
Interactive tool: platform.openai.com/tokenizer
The Transformer architecture (simplified)
Pre-training: learning to predict
What happens
- Input: trillions of words from the internet, books, code
- Objective: predict the next token
- Duration: weeks on thousands of GPUs
- Cost: tens to hundreds of millions of $
What it learns
- Grammar and syntax
- Facts about the world
- Basic logical reasoning
- Different writing styles
Post-training: from predictor to assistant
- SFT — (instruction → ideal response) pairs written by humans
- RLHF — human raters compare responses, the model learns what they prefer
- Result: the model "converses" instead of completing sentences
Generation parameters
| Parameter | Effect | Example use |
|---|---|---|
temperature |
0 = deterministic, 1 = creative, >1 = chaotic | 0.2 for FAQs, 0.9 for copywriting |
top_p |
Truncates to top P% of cumulative probability | 0.9 safe default |
max_tokens |
Limit of generated tokens | 150 for tweets, 2000 for articles |
stop |
String that stops generation | "\n\n" for short responses |
The leading models today
Closed vs open source models
Proprietary (third-party APIs)
- No infrastructure to manage
- Automatic updates
- Variable cost per token
- Data sent to the provider
- Example: OpenAI, Anthropic, Google
Open-source / open-weight
- Full data control
- Fixed cost (hardware)
- Requires technical expertise
- Full customisation
- Example: LLaMA, Mistral, Phi
Consumer-grade interfaces vs API
Consumer-grade interfaces (ChatGPT, Claude.ai, Gemini)
- Manual use, session by session
- No integration with business systems
- Suitable for experimentation and individual use
- Data not used for training (paid plan)
API (OpenAI API, Claude API, etc.)
- Integrable into apps, CRM, PMS, website
- Automatable and scalable
- Requires technical development (or no-code)
- Pay-per-use billing
How to choose a model: criteria for SMEs
- Task quality — use top models only if the task is critical (e.g. responses to VIP guests)
- Cost per call — check the pricing: input and output tokens have different rates
- Latency — real-time chatbots require fast models (e.g. GPT-4o mini, Claude Haiku)
- Language support — test explicitly: not all models perform equally in non-English languages
- Data compliance — verify DPA, data residency (EU), terms of use
Challenge
Context Window
The model's working memory: limits and practical implications
What is the context window
The context window is the maximum amount of text the model can "see" in a single processing moment.
| Model | Context window | ≈ English words |
|---|---|---|
| GPT-4o | 128,000 tokens | ~96,000 |
| Claude 3.5 Sonnet | 200,000 tokens | ~150,000 |
| Gemini 2 Pro | 2,000,000 tokens | ~1,500,000 |
| GPT-4o mini | 128,000 tokens | ~96,000 |
What happens when the context is full
- The model cannot process more text: the API call returns an error
- Some implementations "trim" the oldest parts of the conversation
- The model "forgets" the trimmed information: no native persistent memory
- Response quality degrades if the context is very long (lost-in-the-middle)
Managing context in real applications
Software strategies
- Progressive summarization — summarize the chat every N turns
- Sliding window — keep only the last K exchanges
- RAG — retrieve only the relevant pieces (→ section 5)
- Entity extraction — save important facts to a DB
Cost implications
- Input tokens are charged on every call
- Long conversation = growing cost
- Keeping the system prompt short matters
- Models with caching (Claude) reduce costs
Context window in tourism
| Scenario | Estimated tokens | Strategy |
|---|---|---|
| Booking chatbot (short chat) | 1,000–5,000 | No problem, mini model |
| Analysis of 50 reviews | ~20,000 | Batch, one analysis at a time |
| Q&A on full catalogue (500 products) | >100,000 | RAG required |
| Single reply to a guest | 200–800 | Direct API call, inexpensive |
The trend: growing context windows
- 2023: GPT-4 with 8k → 32k tokens
- 2024: Claude with 200k, Gemini with 1M tokens
- 2025: Gemini 2.0 with 2M tokens (~1,500 pages)
- Direction: "unlimited" context window in the long term
Challenge
Fine-tuning
Training a model on your own data
The adaptation continuum
Training types compared
| Phase | Data | Who does it | Cost |
|---|---|---|---|
| Pre-training | Trillions of tokens from the internet | Labs only (OpenAI, Anthropic…) | $10M–$100M+ |
| Supervised FT | A few hundred to thousands of examples | Companies, developers | $100–$10,000 |
| RLHF / RLAIF | Human or AI preferences | Mainly the labs | High |
| Prompting | Examples in the text | Anyone | API call cost |
Full fine-tuning vs LoRA
Full fine-tuning
- Updates all model parameters
- Maximum adaptation capacity
- Requires high-end GPUs
- Risk of "forgetting" base knowledge (catastrophic forgetting)
LoRA / PEFT
- Adds small adapters to the base model
- Trains only a fraction of parameters (<1%)
- Consumer-grade GPUs are sufficient
- The base model remains intact
- The dominant technique today for local fine-tuning
When fine-tuning is worth it
- The model must adopt a very specific communication style (brand tone, register)
- Repetitive task with a rigid output format (e.g. structured JSON, specific forms)
- Long prompt that repeats every time: fine-tuning "bakes in" the instructions
- You have hundreds of high-quality examples already validated
Requirements: data, costs, infrastructure
Data
- Min. 50–100 examples (quality > quantity)
- Format: JSONL with prompt/completion
- Must be clean and representative
Cost (API)
- OpenAI FT: ~$8 / 1M training tokens
- One-time training + ongoing inference
- Model hosting may have a fixed cost
Infrastructure
- Via API: no infrastructure needed
- Self-hosted: GPU with 16–80 GB VRAM
- Cloud ML: Vertex AI, SageMaker, RunPod
Example: specialised chatbot for a hotel
Without fine-tuning
Prompt: "You are the Hotel Bellavista assistant.
Reply in a warm and professional manner.
Here are our policies: [500 tokens]
Here are our services: [800 tokens]
Guest question: late check-out?"~1,400 tokens of context on every call
With fine-tuning
Prompt: "Guest question:
late check-out?"Tone, policies and style already baked into the model
~30 tokens of context on every call
Fine-tuning vs prompting: the choice
| Criterion | Use prompting | Consider fine-tuning |
|---|---|---|
| Time available | Available immediately | Weeks for data + training |
| Request volume | Low / medium | Very high (context cost) |
| Output style | Generic or semi-specific | Very rigid or branded |
| Available data | Few or none | Tens to hundreds of examples |
| Technical skills | None required | Developer or ML engineer |
Challenge
RAG — Retrieval Augmented Generation
Connecting an LLM to your data without training it
The problem: the LLM doesn't know your data
What the LLM doesn't know
- Your updated price list
- Your hotel's specific policies
- Real-time availability
- Internal company documents
- News from the past few months
The (bad) alternatives
- Put everything in the prompt → context explodes, high costs
- Fine-tuning → doesn't learn updatable facts, only style
- Ignore the problem → the model hallucinates
RAG Architecture — Core concept

RAG Architecture — Application diagram
Embeddings: text as coordinates
An embedding model converts text into a vector of numbers that represents its meaning.
- Texts with similar meaning → nearby vectors in the space
- Cosine similarity measures how semantically related two texts are
- Embedding models: OpenAI text-embedding-3, Cohere, sentence-transformers
Embeddings: the vector space

Embeddings: word vectors

Vector database: what it is and how it works
Traditional database
Searches for exact words
SELECT * FROM faq
WHERE text LIKE '%check-out%'Does not find "departure time"
Vector database
Searches by semantic meaning
query = embed("what time do I need to leave the room?")
results = db.search(query, top_k=3)Finds check-out, departure, late check-out…
Common vector database solutions: Pinecone, Weaviate, Chroma, pgvector (PostgreSQL), Qdrant
RAG pipeline: step by step
- Document loading — PDF, Word, database, website
- Chunking — split into pieces of 200–500 tokens with overlap
- Embedding — convert each chunk into a vector
- Indexing — save the vectors to the vector DB
- — runtime —
- Question embedding — convert the user question into a vector
- Search — find the top-3/5 most similar chunks
- Augmentation — insert the chunks into the prompt
- Generation — the LLM responds based on the chunks
RAG in tourism: practical examples
Dynamic hotel FAQ
- Operations manual → chunked
- Chatbot answers on policies, hours, services
- Update: upload new PDF
Tour catalogue
- 500 tour sheets → indexed
- "Tour suitable for children with snorkeling" → top-3 tours
- Response with precise details
Prices and availability
- Nightly update from the PMS
- Chatbot responds with fresh data
- No risk of outdated information
RAG vs fine-tuning: comparison table
| Aspect | RAG | Fine-tuning |
|---|---|---|
| Data updates | Easy (reload documents) | Expensive (retrain) |
| Transparency | High (source is visible) | Low (data baked in) |
| Factual hallucinations | Reduced (chunks as anchor) | Present |
| Output style | Does not change model behaviour | Modifies style and behaviour |
| Technical setup | Medium (vector DB, pipeline) | Medium-high (dataset, GPU) |
RAG limitations
- Chunking quality — poorly split chunks = fragmented context = wrong answer
- Multi-hop questions — "compare the price of tour X with tour Y" requires multiple retrievals
- Non-textual data — complex tables, images, PDFs with complex layout are difficult
- Added latency — vector search adds 50–300ms per query
- Hallucination not eliminated — the model can still ignore the provided context
Challenge
AI Agents
Autonomous systems that plan and act in the real world
The difference: LLM, Assistant, Agent
- Predicts the next token
- No memory
- No tools
- Responds in natural language
- Maintains context
- Follows system instructions
- Plans complex tasks
- Uses tools and executes actions
- Observes results and iterates
The ReAct cycle: Reason → Act → Observe
Planning and memory in agents
Memory types
- In-context — everything in the current conversation
- External — databases, files, persistent vectors
- Procedural — instructions in the system prompt
- Episodic — logs of previous sessions
Planning types
- Chain-of-thought — step by step in the text
- Tree-of-thought — explores multiple paths
- Plan-and-execute — full plan then execution
- ReAct — interleaves reasoning and actions
Multi-agent systems
Key concepts
- Specialisation — each agent has a precise domain and dedicated tools
- Orchestration — the orchestrator assigns tasks, collects results and resolves conflicts
- Parallelism — multiple agents work simultaneously, reducing latency
- Composability — sub-agents are reusable in other workflows
Frameworks
- LangGraph — agent graphs with explicit state
- CrewAI — agents with roles and goals in natural language
- AutoGen — multi-agent conversations (Microsoft)
- Claude MCP — standard protocol for tools and agents
AI Agents in tourism
🏨 Automated booking
Receives request, checks PMS availability, applies rate policies, generates confirmation and sends email to the guest
💰 Revenue optimisation
Analyses history, local events and competitors → automatically proposes the weekly rate plan to the revenue manager
🔍 Competitor monitoring
Scans OTAs every hour, compares rates with your own, notifies the team if the gap exceeds a defined threshold
⭐ Review management
Monitors TripAdvisor, Google, Booking in real time, drafts personalised replies and sends them after human approval
🗺️ Traveller assistant
Plans tailor-made itineraries, books restaurants and activities, answers pre- and post-stay questions in natural language
📊 Operations reports
Aggregates data from PMS, CRM and OTA channels every morning → generates KPI report with highlighted anomalies, ready for the briefing
Risks and limitations of agents
- Cascading errors — a mistake in one step is amplified in subsequent steps
- Infinite loops — the agent does not terminate if it cannot find the stop condition
- Prompt injection — malicious external data crafted to hijack the agent's behaviour
- Unpredictable costs — every iteration consumes tokens: complex tasks cost a lot
- Irreversible actions — sending emails, modifying databases, spending money
When are agents reliable today?
| Scenario | Reliability | Notes |
|---|---|---|
| Simple tasks with clear tools | High | 1-3 steps, well-defined tools |
| Information search and synthesis | High | No irreversible actions |
| Multi-step workflow (5-10 steps) | Medium | Requires supervision |
| Open-ended tasks, ambiguous goal | Low | Not recommended in production |
| Autonomous financial actions | Not recommended | Human supervision always |
Challenge
Tools and Function Calling
How an LLM executes actions in the real world
From the LLM to the real world
An LLM on its own only produces text. To do something, it needs tools.
Function calling: defining tools for the LLM
Each tool is defined with a schema that the model uses to generate correct calls.
{
"name": "check_availability",
"description": "Checks room availability in the PMS",
"parameters": {
"room_type": {
"type": "string",
"enum": ["standard", "deluxe", "suite"],
"description": "Requested room type"
},
"arrival_date": {
"type": "string",
"format": "date",
"description": "Arrival date (YYYY-MM-DD)"
},
"nights": {
"type": "integer",
"description": "Number of nights"
}
},
"required": ["room_type", "arrival_date", "nights"]
}Tool examples in tourism
| Tool | Action | Integrated system |
|---|---|---|
check_availability |
Check available rooms | PMS (Opera, Mews, Cloudbeds) |
create_booking |
Book and confirm | PMS + Channel Manager |
get_weather |
Weather forecast for destination | Weather API |
send_notification |
Email/SMS to the guest | CRM, Mailchimp, Twilio |
update_rate |
Update prices | Revenue management system |
Multi-agent architecture
MCP: Model Context Protocol
MCP is an open standard (Anthropic, 2024) for connecting LLMs to tools and data sources in an interoperable way.
Before MCP
- Every integrator builds their own format
- Tools not reusable across different models
- Multiplied maintenance
With MCP
- Standard MCP server for each system
- Works with Claude, GPT-4, Gemini…
- Ecosystem of ready-made servers (Google Drive, GitHub, databases…)
Classic function calling: context overhead
- Every intermediate result enters the context: the model must process each response before proceeding
- With N sources: 2N + 1 round-trips, context usage O(N)
- Saturated context → performance degradation (lost-in-the-middle); latency and cost grow linearly
Programmatic Tool Calling
Classic function calling
Programmatic Tool Calling
# The model generates this code:
results = web_search("AI news")
content_list = []
for r in results:
content = web_fetch(r.url)
content_list.append(content)
write_blog(content_list)1 round-trip · only the final output re-enters the LLM context
Code Execution: enabling and impact
How to enable it (Anthropic API)
tools = [
# 1. Add the execution environment
{"type": "code_execution_20250522",
"name": "code_execution"},
# 2. Mark tools callable from code
{
"name": "query_database",
"description": "...",
"input_schema": {...},
"allowed": ["code_execution"]
}
]The code_execution tool provides the sandbox; allowed exposes the function as callable in the environment.
Unlocked capabilities
- Batch processing —
forloops over N elements, executed in parallel - Conditional tool selection —
if/elseon the result of a tool to decide the next tool - Local data filtering — transformation and aggregation of results before inserting them into context
- Round-trip reduction — from 2N+1 calls to 1 (request) + 1 (final response)
Anthropic benchmark: context at equivalent task approximately 4× lower compared to classic function calling.
Advanced optimisations for high-efficiency agents
Dynamic Web Filtering
- The system automatically filters the content of web pages retrieved during web search
- Only semantically relevant sections for the query enter the context
- Input token reduction: 24% on average (range 33–62% depending on content)
- Activation: add the
web_searchtool — filtering is applied automatically
Tool Search
- With many MCP servers, loading all definitions into context is prohibitive
- A special
search_toolsearches for relevant definitions on demand, via regex or BM25 query - Savings: ~95% of context occupied by tool definitions
- Deferred loading: the definition is loaded only when needed and removed afterwards, freeing space
Tool Use Examples
- Add input examples to the tool definition (few-shot approach at schema level)
- Five examples are sufficient in most cases
- Accuracy in correct tool invocation: 70% → 90%
- Particularly useful for tools with many parameters or complex structured inputs
Challenge
Lunch
Resuming in the afternoon
AI Tools: practical guide
ChatGPT, Claude, Copilot and Gemini — access, costs and first hands-on activities
The consumer tools landscape
| Tool | Company | Key strength | Free? |
|---|---|---|---|
| ChatGPT | OpenAI | General purpose, the best-known; images (DALL-E 3) | Yes (limited) |
| Claude.ai | Anthropic | Long-form writing, PDF document analysis | Yes (limited) |
| Microsoft Copilot | Microsoft | Integrated in Outlook, Teams, Excel, Word | Yes (web) |
| Google Gemini | Integrated in Gmail, Docs, Drive, Sheets | Yes (basic) |
ChatGPT — chatgpt.com
For tourism
- Responding to positive and negative reviews
- Writing social posts (Instagram, Facebook)
- Creating personalised itineraries on request
- Translating communications into multiple languages
- Generating room and package descriptions
Plans
- Free — GPT-5.2 limited
- Plus — $20/month · GPT-5.2 unlimited, files, images
Go to chatgpt.com → paste a recent negative review → write:
"Reply in a professional and empathetic tone, in 100 words or fewer."
Claude.ai — claude.ai
For tourism
- Analysing long documents (contracts, policies, PDFs)
- Answering questions about the content of a document
- Writing articulate texts in the brand's tone of voice
- Summarising feedback and identifying patterns
- Reasoning through complex scenarios (pricing decisions, offers)
Plans
- Free — Claude Sonnet, Haiku (limited daily use)
- Pro — $18/month · Claude Opus, extended use, files, Projects
Go to claude.ai → upload your cancellation policy PDF → write:
"If a guest cancels 8 days in advance, are they entitled to a refund? Answer clearly and concisely."
The Projects feature (Pro plan) saves a fixed context — policy, tone, instructions — without having to rewrite it for every conversation.
Microsoft Copilot — copilot.microsoft.com
For tourism
- Outlook — draft welcome, pre-arrival and follow-up emails
- Teams — meeting summary with action items
- Excel — booking data analysis, occupancy charts
- Word — standard contracts, commercial proposals
- Web (free) — search with sources, real-time answers
Plans
- Free — copilot.microsoft.com (GPT-5.1 + web search)
- M365 Copilot — $30/user/month · integrated in Office apps
Go to copilot.microsoft.com → write:
"Write a welcome email for a guest arriving tomorrow at my boutique hotel in Florence. Warm tone, max 80 words."
If you already use Microsoft 365, check with your IT provider whether the M365 Copilot plan can be activated on your tenant.
Google Gemini — gemini.google.com
For tourism
- Gmail — draft replies to booking enquiries
- Google Docs — generating proposals, local guides, press releases
- Google Sheets — data analysis with natural language
- Real-time web search (competitor prices, local events)
- Image analysis — property photos, menus, decor
Plans
- Free — Gemini 2.5 Flash on gemini.google.com
- Google One AI Premium — €21.99/month · Gemini 3.1 Pro + Workspace
Go to gemini.google.com → paste 5–10 recent reviews → write:
"Analyse these reviews: list the 3 most-mentioned strengths and the 2 most-mentioned areas for improvement."
Those already using Google Workspace get the most value from the paid plan, thanks to native integrations with Gmail and Drive.
Which tool to choose
| If… | Use | Plan |
|---|---|---|
| You already use Microsoft 365 (Outlook, Teams, Excel) | Microsoft Copilot M365 | $30/user/month |
| You already use Google Workspace (Gmail, Drive) | Google Gemini | €21.99/month |
| You want to analyse documents and write articulate texts | Claude.ai | Free to start, Pro ($18/month) for daily use |
| You want the most versatile option, with image generation | ChatGPT | Free to start, Plus ($20/month) for daily use |
Challenge
Identifying Opportunities
Where AI creates value in your tourism business
Framework: mapping repetitive processes
The starting point for identifying AI opportunities is a map of repetitive business processes.
Signals that a task is suitable for AI
- It repeats more than 10 times a day
- It requires text / language processing
- It has a definable and verifiable output
- A new team member would learn it in < 1 hour
- It does not require deep empathy or a personal relationship
Signals that a task is NOT suitable
- Each case is unique and complex
- It requires ethical or legal judgement
- It involves a human relationship as the core value
- Errors have serious consequences
- Pure structured data (use a traditional database instead)
Impact / effort matrix for AI
- Quick wins: review responses, social post generation, FAQ chatbot, guest email translation
- Strategic: AI revenue management, automated bookings, RAG on catalogue, multichannel agent
Suitable vs not suitable for generative AI
| Suitable | Not suitable (or not yet) |
|---|---|
| Responding to template emails with personalisation | Managing complex disputes with guests |
| Generating room / package descriptions | Legal decisions (refunds, damages) |
| Summarising feedback and reviews | Physical operational supervision |
| Proposing personalised itineraries | Relationships with high-value VIP clients |
| Translating multilingual communications | HR performance evaluations of staff |
Use cases by sector
Hotel / B&B
- Booking and FAQ chatbot
- Automated check-in/out via chat
- Automated review responses
- Personalised pre-arrival upsell
- Monthly feedback summary
Restaurants
- Generating menu descriptions
- Responding to bookings and dietary requests
- Automated social posts
- TripAdvisor review analysis
Travel agencies / DMC
- Personalised itinerary proposals
- Supplier research and comparison
- Automated follow-up emails
- Client briefing processing
Exercise: identify 3 processes in your business
- Think about the tasks you (or your team) carry out repeatedly every week
- For each one, assess: High/Medium/Low frequency × High/Medium/Low impact if automated
- Position it on the impact/effort matrix
| Task | Frequency | Impact | Estimated effort |
|---|---|---|---|
| 1. | |||
| 2. | |||
| 3. |
Challenge
Effective Prompting
Communicating with AI models precisely and systematically
Anatomy of a prompt: 5 components
Zero-shot, few-shot, chain-of-thought
Zero-shot
No examples, instruction only
"Classify this review as positive or negative: 'The breakfast was cold'"
Fast, cheap, sufficient for simple tasks
Few-shot
2–5 examples before the task
"Positive: 'Breathtaking view' Negative: 'Small room' Classify: 'Cold breakfast'"
Improves precision and output format
Chain-of-thought
Ask for explicit reasoning
"Reason step by step: 1) Identify the problem 2) Assess the tone 3) Give the classification"
Complex tasks, reasoning, calculations
Prompt templating: reusable structures
A template is a prompt with variables to be filled in at runtime.
You are the guest relations manager of {{property_name}}.
You have received this review on {{platform}}:
---
{{review_text}}
---
Write a professional response that:
- Thanks the guest for their feedback
- Addresses the main point specifically
- {{specific_instruction}}
- Stays under {{max_words}} wordsPractical example: social post
Prompt
"You are the social media manager of Agriturismo Le Colline. Write 3 Instagram post variants to promote the wine-tasting weekend on 15 March. Format: - Emoji at the start - Max 150 characters - 3–5 relevant hashtags - Warm, authentic tone"
Expected output
🍷 Saturday, 15 March, join us among our vineyards for an unforgettable wine tasting. #agriturismo #wine #tuscany 🌿 A weekend of flavour and nature: tasting with a view over the hills. Limited spots! #wine #tuscany #weekend ✨ Every sip tells the story of our land. Join us on 15 March. #winetasting #wine #italianwine
Practical example: replying to reviews
Review (negative)
Prompt
"Reply to this negative review. Tone: professional and understanding. Acknowledge the specific issues. Offer a direct point of contact. Max 100 words. Do not be defensive."
Output
Practical example: personalised itineraries
You are an expert in eastern Sicily tourism.
Create a 5-day itinerary for:
- Couple, aged 35–40
- Interests: Greco-Roman history, local cuisine, moderate walks
- Budget: mid-to-high
- Period: April
- Base: Syracuse
- Self-guided: independent travel by car
For each day indicate:
- Morning / afternoon / evening
- Estimated driving time
- 1 recommended restaurant with a typical speciality
- 1 practical note (booking recommended, opening hours, etc.)Practical examples: FAQ and descriptions
Automated FAQ
"Given this cancellation policy: [policy text] Answer this guest question: 'If I cancel 10 days in advance do I get a full refund?' Be precise, brief, and friendly in tone."
Package description
"Write a commercial description for this package: - 3 nights sea-view suite - Breakfast included - Unlimited SPA access - Romantic dinner (1 evening) - Price: €480 per night Target: couples, special occasions. Max 80 words. Evocative tone."
Common mistakes in prompting
| Error | Effect | Solution |
|---|---|---|
| Prompt too vague | Generic, unusable output | Specify format, length, tone |
| No business context | Generic, non-branded response | Add name, sector, values |
| Only saying what NOT to do | The model doesn't know what to do | Say WHAT you want, not just what to avoid |
| Multiple tasks in one prompt | Mediocre result on everything | One prompt = one task |
| No output structure | Unpredictable format | Specify: "reply as a list", "use JSON" |
Systematic prompt debugging
Prompt for review analysis
Analyse the following hotel reviews and produce a structured report.
Reviews:
---
{{reviews_list}}
---
For each review, identify:
1. Overall sentiment: Positive / Neutral / Negative
2. Main themes mentioned (max 3 per review)
3. Implicit score 1–5
Then produce:
- Top 3 recurring strengths
- Top 3 areas for improvement
- 1 concrete recommended action
Output format: structured JSONPrompt Engineering vs. Context Engineering
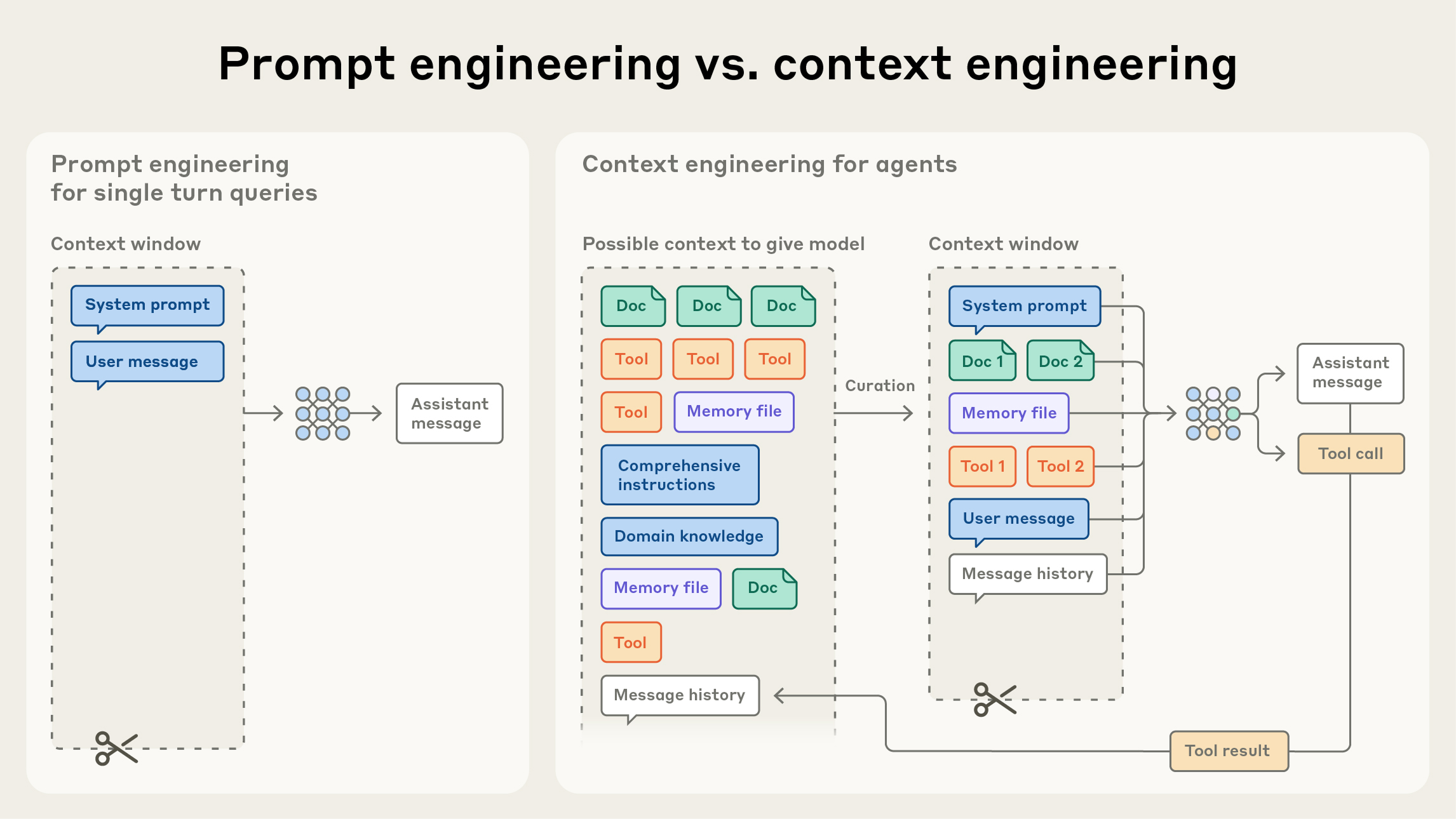
Prompt Engineering
Optimising the text of a single prompt: role, instruction, format, constraints, few-shot examples.
Context Engineering
Designing the entire context passed to the model:
- Tools — which tools are available and with what definitions
- Retrieved documents — RAG chunks, web results, project files
- Conversation history — which turns to keep or compress
- Structured outputs — previous tool call results in the context
Challenge
Security and Privacy
GDPR, practical risks and responsible AI use
GDPR and AI: obligations and responsibilities
Relevant GDPR principles
- Data minimisation — use only necessary data
- Purpose limitation — do not reuse data for other purposes
- Accountability — you are the data controller
- Privacy by design — design with privacy in mind
What changes with AI
- Data sent to the API may be used for training (check the terms)
- Automated decisions require transparency (Art. 22)
- Guest profiling → legal basis required
- Data breach includes leaks via prompts
Specific risks: what can go wrong
| Risk | Description | Impact |
|---|---|---|
| Prompt injection | A malicious input alters the model's behaviour | Exposed data, unauthorised actions |
| Data leakage | The model "remembers" sensitive data inserted in the context | Exposure of client/business data |
| Model inversion | Attacks that extract data from model parameters | Relevant only for fine-tuning on sensitive data |
| Hallucinations in factual data | The model invents prices, policies, legal information | Reputational damage, disputes |
Practical rules: what to never include in a prompt
- Personally identifiable data (name + email + phone together)
- Credit card numbers, banking details, identity documents
- Access credentials (passwords, API keys, tokens)
- Health data or sensitive guest preferences
- Trade secrets or confidential contracts
For batch processing of client data: always use pseudonymisation and keep the mapping locally.
AI services with enterprise guarantees
Enterprise options
- OpenAI Enterprise / API — data not used for training, SOC 2
- Azure OpenAI — EU data residency, tenant isolation, Microsoft DPA
- Anthropic Claude API — data not used for training, robust privacy policy
- Google Vertex AI — data residency, GDPR compliance
What to verify
- Is data used for training? (no for paid plans)
- Where is data processed? (data residency)
- Is a DPA (Data Processing Agreement) available?
- Certifications: SOC 2, ISO 27001, GDPR?
Checklist: safe AI use in a tourism SME
- I have signed a DPA with the AI provider
- Shadow AI policy: staff must not include personal client data in prompts
- I use paid plans only (no training on data)
- I have updated the data processing register
- Privacy policy updated (mention of AI tools)
- AI outputs reviewed by a human before sending
- No API keys in website / app code
- Access to AI tools restricted to necessary users
- Auditing: logs of critical AI operations retained
- Data breach response plan updated
Challenge
Day 1 Closing
Recap · Resources · Next steps
Recap — Technical foundations
Key concepts
- LLM = statistical prediction at enormous scale
- Token = basic unit of cost and context
- Context window = the model's working memory
- Fine-tuning = style and format, not new facts
- RAG = your data + LLM without training
- Agents = LLM + tools + limited autonomy
- Function calling = interface between LLM and real systems
Recap — Strategy and prompting
Identifying opportunities
- Repetitive processes with definable output
- Impact/effort matrix
- Quick wins first
Effective prompting
- 5 components: Role, Context, Task, Format, Constraints
- Reusable templates
- Iterate one element at a time
Security
- No sensitive data in prompts
- DPA with the provider
- Human review of critical outputs
Resources for further reading
Reading
- The Alignment Problem — Brian Christian
- Co-Intelligence — Ethan Mollick
- Anthropic Research Blog
- OpenAI Research
- Claude API Docs — technical guides and in-depth concepts
Online courses
- deeplearning.ai — practical courses, free
- fast.ai — applied ML
- Prompt Engineering Guide
Tools to explore
- Claude.ai — Anthropic interface
- ChatGPT — OpenAI interface
- Perplexity — AI-powered search
- Make / n8n — no-code AI automations
- Dify / Flowise — no-code RAG and chatbots
Community
- r/LocalLLaMA (Reddit)
- Hugging Face community
Questions?
Thank you for today.
See you on Day 2.
Glossary
Abbreviations and terms used during the day
Key abbreviations and terms
Tourism & Business
| OTA | Online Travel Agency — online booking platforms (Booking.com, Expedia, Airbnb) |
| PMS | Property Management System — hotel management software for bookings, rooms and billing |
| CRM | Customer Relationship Management — system for managing client data and relationships |
| KPI | Key Performance Indicator — key metric for measuring business performance |
| FAQ | Frequently Asked Questions — common questions with pre-written answers |
| DMC | Destination Management Company — local operator organising on-site tourism services |
| B2B / B2C | Business-to-Business / Business-to-Consumer — type of commercial relationship |
AI & Technology
| LLM | Large Language Model — AI model trained on large amounts of text |
| ML | Machine Learning — AI discipline that learns from data without explicit rules |
| RAG | Retrieval Augmented Generation — technique that connects an LLM to external documents |
| API | Application Programming Interface — interface for communication between software systems |
| MCP | Model Context Protocol — Anthropic standard for connecting AI agents to external tools |
| GPU | Graphics Processing Unit — specialised processor used for training AI models |
| GDPR | General Data Protection Regulation — EU regulation on personal data protection |
| DPA | Data Processing Agreement — contractual agreement on data processing with third-party providers |
| SOC 2 | Service Organization Control 2 — security certification for cloud service providers |